Problem
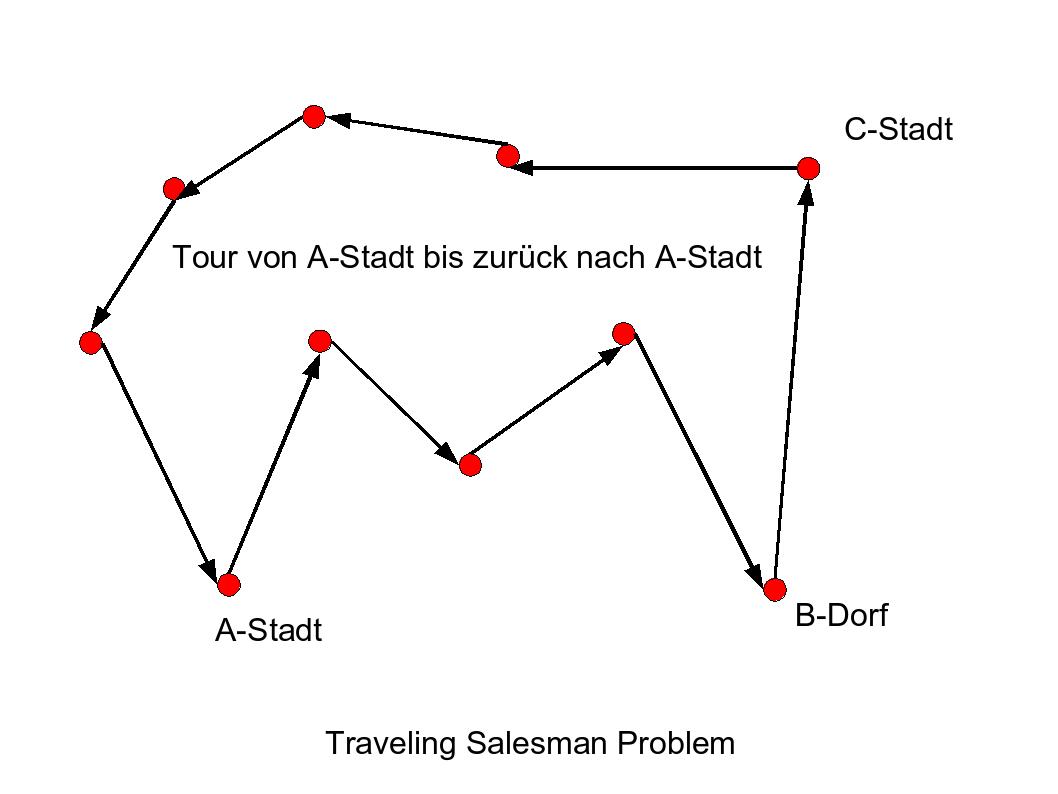
Ein Handlungsreisender will n Städte in einer kürzesten Tour besuchen. Es gibt viele ähnliche Anwendungen.
Modellierung durch einen Graphen mit n Punkten (Ecken/Vertices) und Verbindungen (Kanten/Edges) zwischen allen Punkten.
Jede Verbindungen zwischen zwei Ecken hat bestimmte (Fahrt-)Kosten.
Eine Tour ist ein Pfad im Graphen, der alle Punkte umfasst und zum Ausgangspunkt zurückkehrt.
Problem: finde eine Tour mit den niedrigsten (Fahrt-)Kosten.
Das Finden einer Lösung ist NP-vollständig.
Exakte Lösung: durch Aufzählen aller möglichen Touren und heraussuchen der Tour mit den niedrigsten Kosten. Aufwand O(n!) ~ O((n/e)n+1/2).
Näherungslösungen: ausgehend von einem Spanningtree ausprobieren von kostengünstigeren Touren. Genetische Algorithmen, Simulated Anneahling. Aufwand für erste Näherung O(n2).
Exakte Algorithmen: Branch and Bound/Cut. Wenn der Anfang einer Tour schon höhere Kosten hat als die beste bekannte Tour, wird der weiter Suchzweig abgeschnitten.
Parallele exakte Algorithmen: Verwendung von zentralen und lokalen Arbeitsstapel (Workpiles).
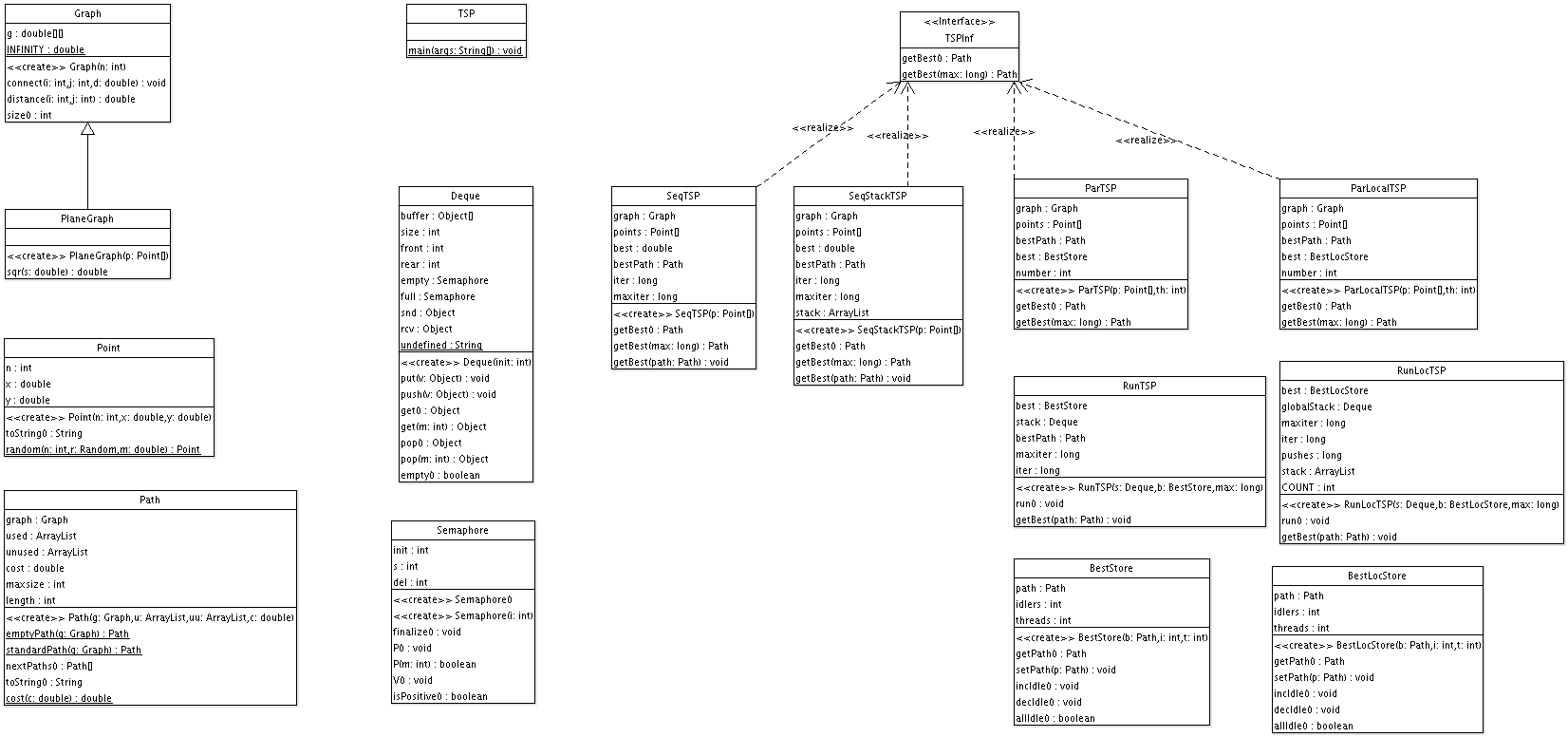

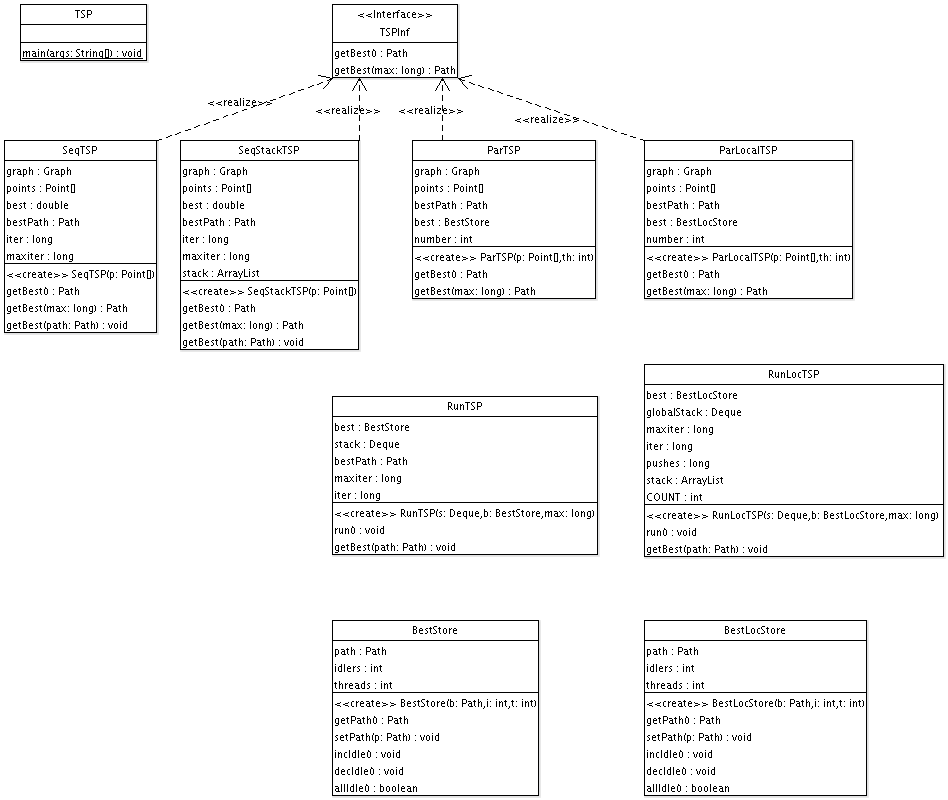
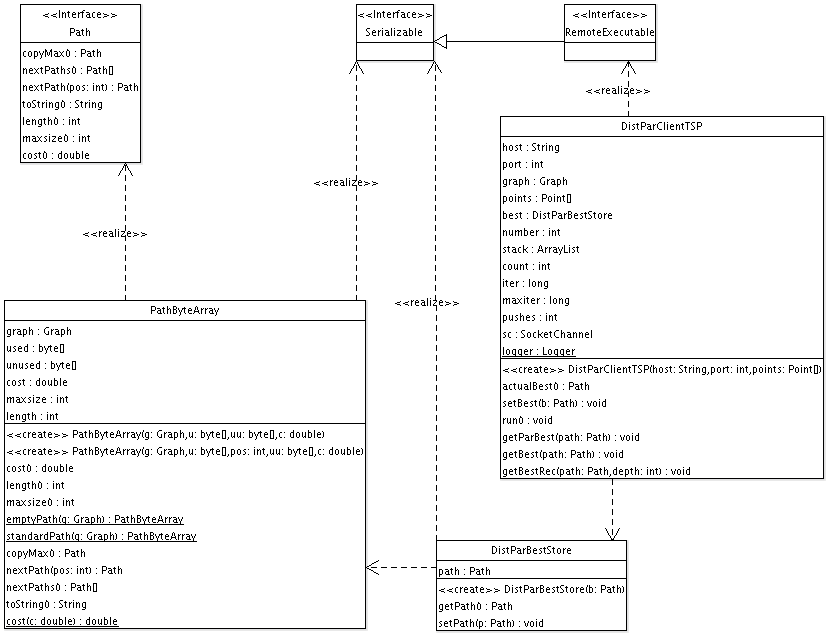
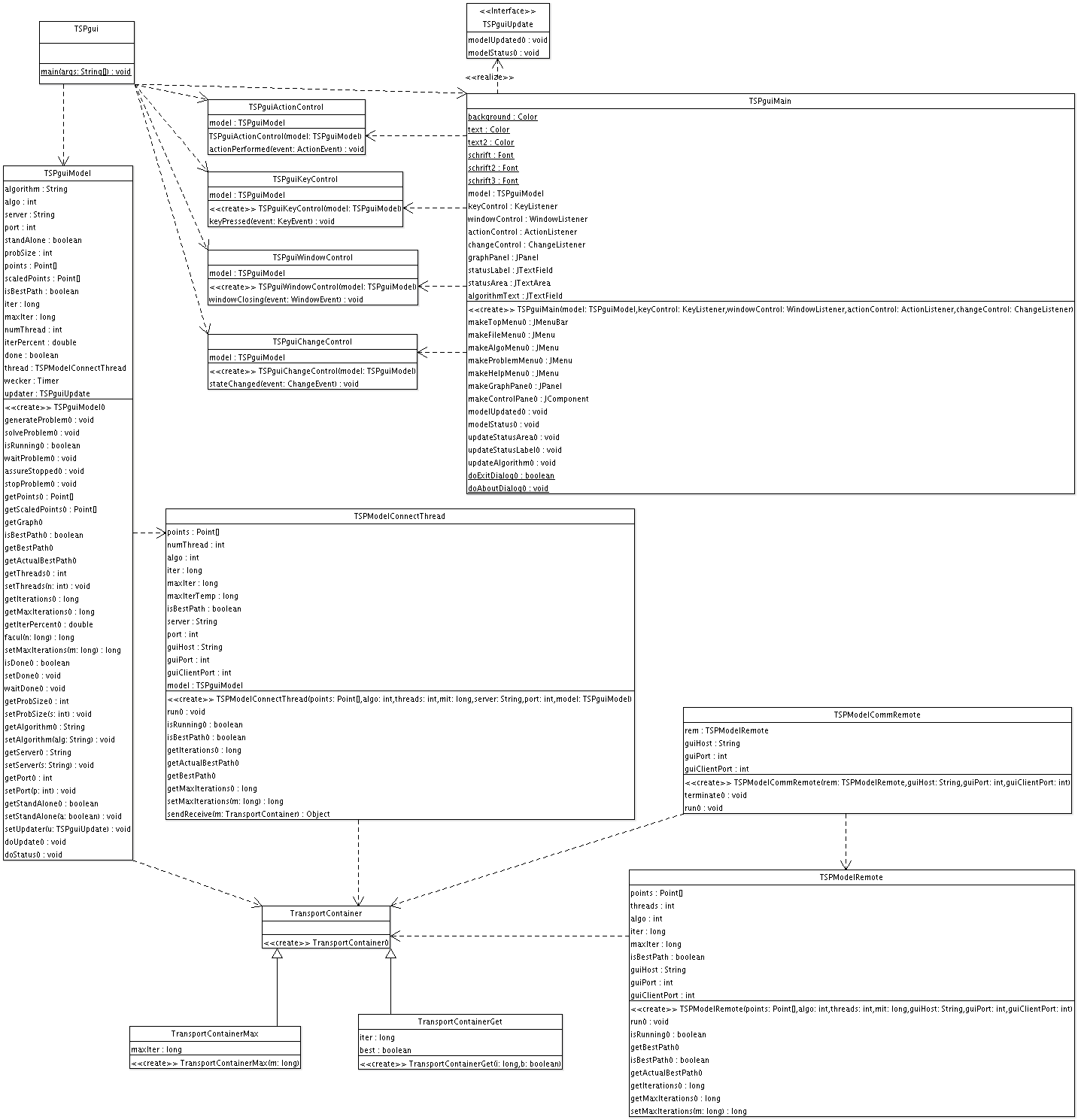
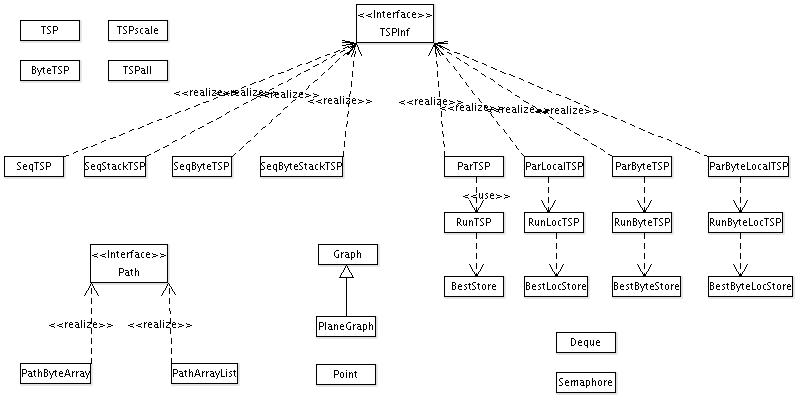 Überblick über alle Klassen
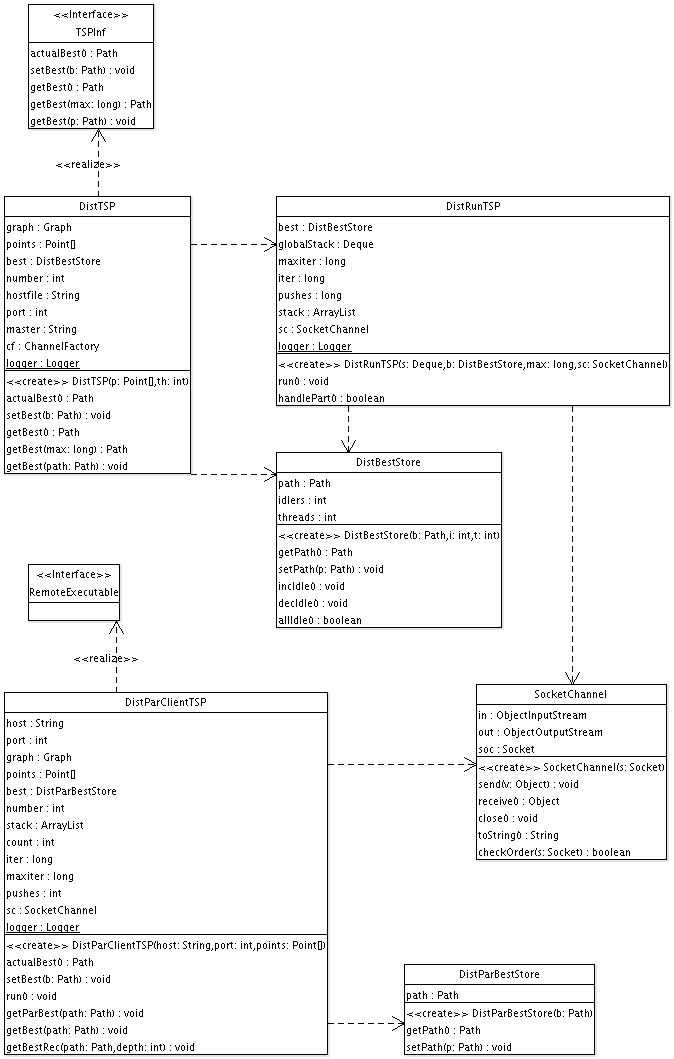
Überblick über alle Klassen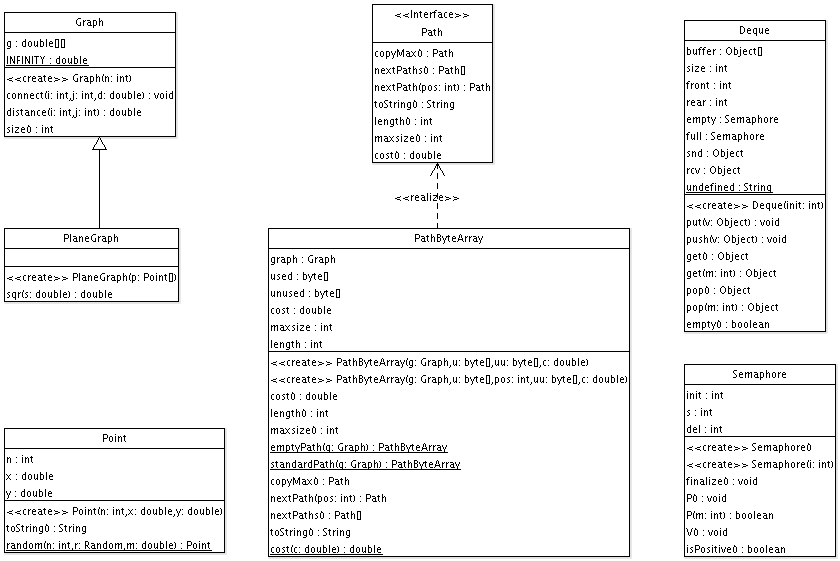
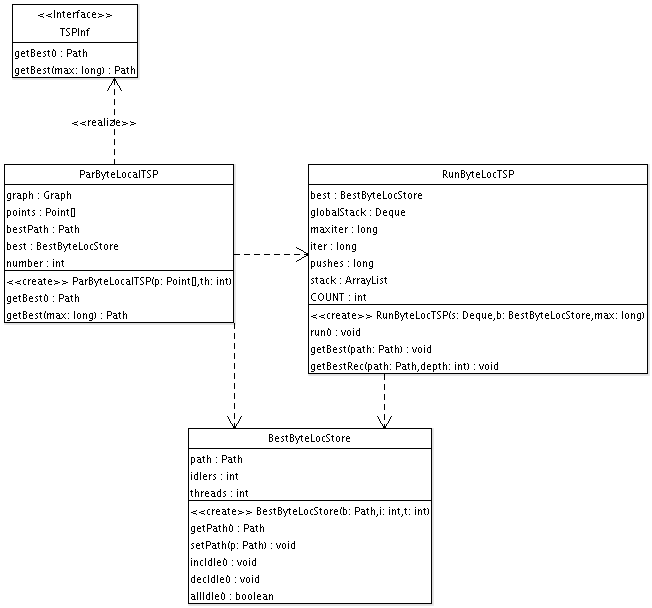
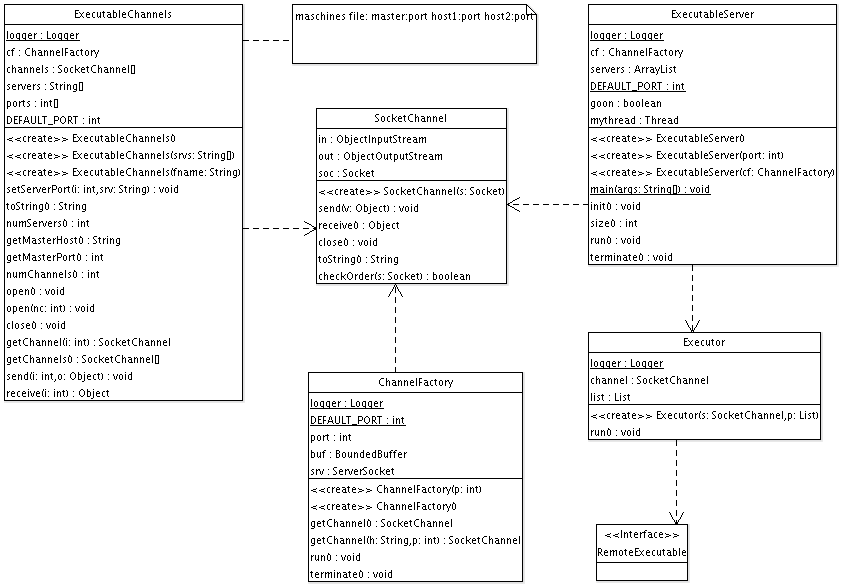
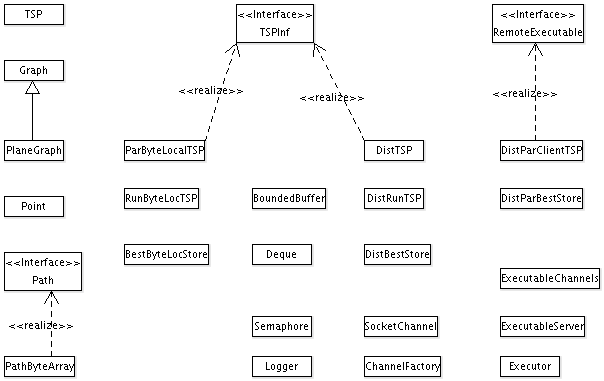 Überblick über alle Klassen
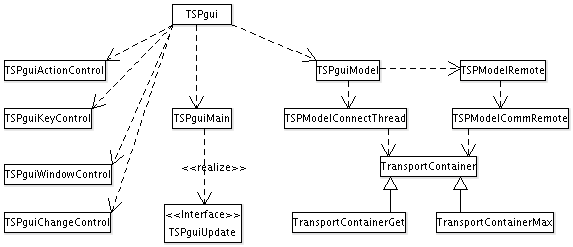
Überblick über alle Klassen