bisher Implementierungsmittel vorgestellt
einige allgemeine Verfahren und Ansätze, wie eine gegebene Aufgabe oder ein gegebener sequentieller Algorithmus parallelisiert werden kann
- Master - Slave, Meister - Geselle
- Client - Server, Kunde - Dienstleister
- Workpile, Arbeitsstapel
- Pipelining, Fließband
- Recursion, Divide and Conquer
Für jedes Verfahren typische Einsatzfelder
- Effizienz von parallelen Programmen
- nicht nur viele Prozessoren einsetzen
- sondern alle Prozessoren müssen gleichmäßig und kontinuierlich ausgelastet werden
- Lastbalancierung
- Effizienz wird verringert:
- Overhead für Erzeugen und Starten
- notwendige Synchronisation
- Verzögerungen bei dem Austausch von Informationen
4.1 Meister-Geselle
Ein Hauptprogramm (Meister) erzeugt und beauftragt Threads (Gesellen), die bestimmte von ihm angegebene Aufgaben bearbeiten.
Charakteristisch ist:
- Die Aufgabe ist genau spezifiziert und hat eine feste Größe (von Beginn an).
- Die Aufgabe läßt sich in genau definierte unabhängige Teilaufgaben zerlegen.
- Alle Teilaufgaben haben die gleiche Größe (bezüglich der Laufzeit und der Ressourcen).
- Das Hauptprogramm faßt am Ende alle Teilergebnisse zusammen.
Durch die Regelmäßigkeit der Aufgabe und des Verfahrens läßt sich eine gute Lastbalancierung und damit auch eine hohe Effizienz erreichen.
Beispiele Matrixmultplikation oder Vektoroperationen. z.B. bei einer Vektorsumme wird die Summation von z.B. 1000 Zahlen auf zehn Threads verteilt, so daß jeder Thread genau 100 Zahlen zu addieren hat. Der Hauptthread hat dann noch die zehn Teilsummen zu addieren, um das Endergebnis zu erhalten.
Das Meister-Geselle-Verfahren ist schlecht anwendbar wenn:
die Aufgaben schlecht strukturiert und von unterschiedlichem Aufwand sind
In diesem Fall kann eben auch nur eine schlechte Lastbalancierung erreicht werden.
Varianten des Meister-Geselle-Verfahrens sind
- Farming-Out-Verfahren
- Divide-and-Conquer-Verfahren
oft auch rekursiv
4.2 Client-Server
im Internet der meist verwendete Ansatz
Ein Server (Dienstleister) bietet auf bekannten Kanälen Dienste an.
Clients stellen eine Verbindung zu diesen Kanälen her und nehmen entsprechend dem Protokoll des Kanals den angebotenen Dienst in Anspruch.
Typischerweise in folgenden Fällen eingesetzt
- Die Anzahl der Clients ist nicht oder nur schwer zu bestimmen.
- Die Aufgaben sind eventuell nicht unabhängig voneinander, z.B. werden einige Details nur nachgefragt, wenn deren Information für den Client wichtig ist.
- Der Umfang der nachgefragten Leistungen variiert oder ist nicht genau bestimmbar, z.B. eine Web-Seite oder ein ganzer Teilbaum von Web-Seiten wird nachgefragt.
- Ein Client nimmt zum Teil die Leistungen mehrerer Server in Anspruch, bis die Aufgabe gelöst ist, z.B. Suchmaschine, Web-Server, FTP-Server.
Die Effizienz ist im allgemeinen niedriger, als bei Meister-Geselle, da eine große Zahl von Servern bereitsteht, die aber unregelmäßig beschäftigt werden.
Ein Beispiel ist etwa das Produzenten-Konsumenten-Problem, bei dem Produzenten oder Compute-Server eine Dienstleistung anbieten und Konsumenten diese Leistungen in Anspruch nehmen.
Ein weiteres Beispiel ist Remote Method Invocation (RMI) von Java. Dabei verwenden Clients im voraus verabredete Methoden auf entfernten Servern.
4.3 Arbeitsstapel
Das Workpile- oder Arbeitsstapel-Verfahren benutzt einen Stapel von Arbeitsaufträgen.
Diese Aufgaben werden von Threads oder Prozessen entnommen, bearbeitet, und dann werden die Ergebnisse an einer geeigneten Stelle abgelegt.
Dann entnimmt der Thread oder Prozeß die nächste Aufgabe, und so weiter.
Das Verfahren kann zusammen mit Threads eingesetzt werden, dann kann ein Bounded Buffer als Stapel benutzt werden;
oder es kann auch mit verteilten Prozessen verwendet werden, dann kann der Stapel durch einen Kanal realisiert werden.
Arbeitsstapel eignet sich besonders unter folgenden Voraussetzungen:
- Die Aufgabe läßt sich in gut definierte unabhängige Teilaufgaben zerlegen.
- Die Teilaufgaben haben eventuell verschiedene Größe (bezüglich der Laufzeit und der Ressourcen).
- Die Anzahl der Teilaufgaben variiert, oder bei der Bearbeitung der Teilaufgaben entstehen neue Teilaufgaben.
- Die Anzahl der Teilaufgaben ist deutlich größer als die Anzahl der eingesetzten Threads oder Prozesse.
Mit diesem Verfahren läßt sich auch für variierende Teilaufgaben eine recht hohe Effizienz erreichen, da Threads oder Prozesse, die sonst untätig sind, sich sofort wieder neue Teilaufgaben besorgen.
Die Lastbalancierung wird damit verbessert und somit auch die Effizienz.
Zur Implementierung des Aufgabenstapels werden meist Bounded Buffer verwendet, es können aber auch Arrays etc. verwendet werden. Wichtig ist eine gewisse Synchronisation der Entnahme und des Einfügens von Aufgaben:
Es soll die gleiche Aufgabe nicht mehrfach erzeugt werden, und eine Aufgabe soll auch nicht mehrfach entnommen werden können.
Bei verteilten Prozessen übernimmt ein Prozeß meist die Verwaltung des Stapels, und die Mitarbeiter holen sich die Aufgaben von einem verabredeten Kanal.
Der Vorteil von Arbeitsstapel liegt darin, daß sich auch bei wechselnder Anzahl und wechselndem Aufwand von Aufgaben eine gute Lastenverteilung erreichen läßt.
Wenn zum Beispiel beim Meister-Geselle-Ansatz ein Thread länger für eine Aufgabe benötigt als die anderen, muß der Master auf das Ergebnis warten und die restlichen Threads beanspruchen eventuell unnötig die Prozessoren.
Durch einen zusätzlichen Booleschen Indikator kann bei Bedarf auch der Inhalt des Arbeitsstapels invalidiert werden. Zum Beispiel bei Tiefensuche in Bäumen, wobei die Suche in einem Teilbaum eine Aufgabe definiert; hier kann die Suche abgebrochen werden (global oder lokal in einem Teilbaum), falls ein Element mit den gesuchten Eigenschaften gefunden ist.
4.4 Pipelining
Aufteilung der Aufgaben durch aufteilen der sequentiellen Abarbeitung
Die Threads oder Prozesse sind auf jeweils eine sequentielle Teilaufgabe spezialisiert. Sie erhalten von vorhergehenden Threads oder Prozessen teilweise vorverarbeitete Daten, die von ihnen um eine Stufe weiterverarbeitet werden. Danach werden die Teilergebnisse an den nächsten Thread oder Prozeß weitergegeben.
Pipelining ist unter folgenden Bedingungen gut einsetzbar:
- Die Aufgabe läßt sich in eine gut definierte sequentielle Folge von Teilaufgaben zerlegen.
- Alle Teilaufgaben haben etwa die gleiche Größe (bezüglich der Laufzeit und der Ressourcen).
- Die Anzahl der Teilaufgaben unterliegt keiner Bedingung, sie kann fest oder variabel sein.
- Die Anzahl der Teilaufgaben entspricht etwa der Anzahl der eingesetzten Threads oder Prozesse.
Falls die Aufgabe oft zu lösen ist, können die zuerst gestarteten Threads schon wieder an einer neuen Aufgabe arbeiten, während die zuletzt gestarteten Threads noch mit der alten Aufgabe beschäftigt sind.
Ein Beispiel für diese Methodik ist etwa die Berechnung des Winkels zwischen zwei sehr langen Vektoren. Die Pipeline besteht dort aus zwei Stufen, die hintereinander ausgeführt werden mußten: Lesen der Vektoren von der Festplatte und anschließende Bildung des Skalarprodukts. Diese Stufen werden für jede reelle Zahl wie am Fließband durchlaufen.
Wenn der Puffer zwischen den Stufen nur mit der Größe 1 gewählt ist, so arbeiten die beiden Stufen sehr gut im Gleichtakt. Mit einem größeren Zwischenpuffer erreicht man eine bessere Entkoppelung der Pipeline-Stufen.
Ein anderes Beispiel für Pipelining, ist das Sortieren einer Folge von ganzen Zahlen (Integer Sort). Dieses Beispiel hat den Vorteil, daß es sich auf beliebig viele Threads bzw. Prozesse verteilen läßt.
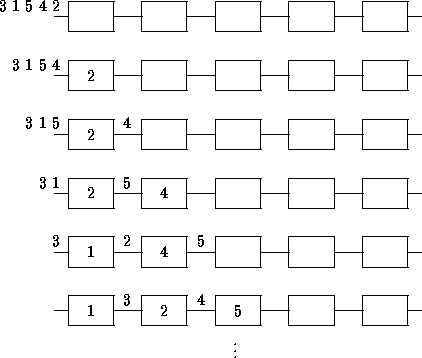
Die meisten sonst gebräuchlichen Pipeline-Probleme haben nur eine begrenzte kleine Anzahl von Stufen. Zwei, wie oben in dem Vektor-Winkel Problem, oder in anderen Fällen auch einmal drei oder vier Stufen.
Parallel-Streams in Java 8
Siehe Abschnitt über java.util.concurrent und java.util.stream.